Apache Kafka - распределённый программный брокер сообщений, проект с открытым исходным кодом, разрабатываемый в рамках фонда Apache. Написан на языке программирования Scala и Java.
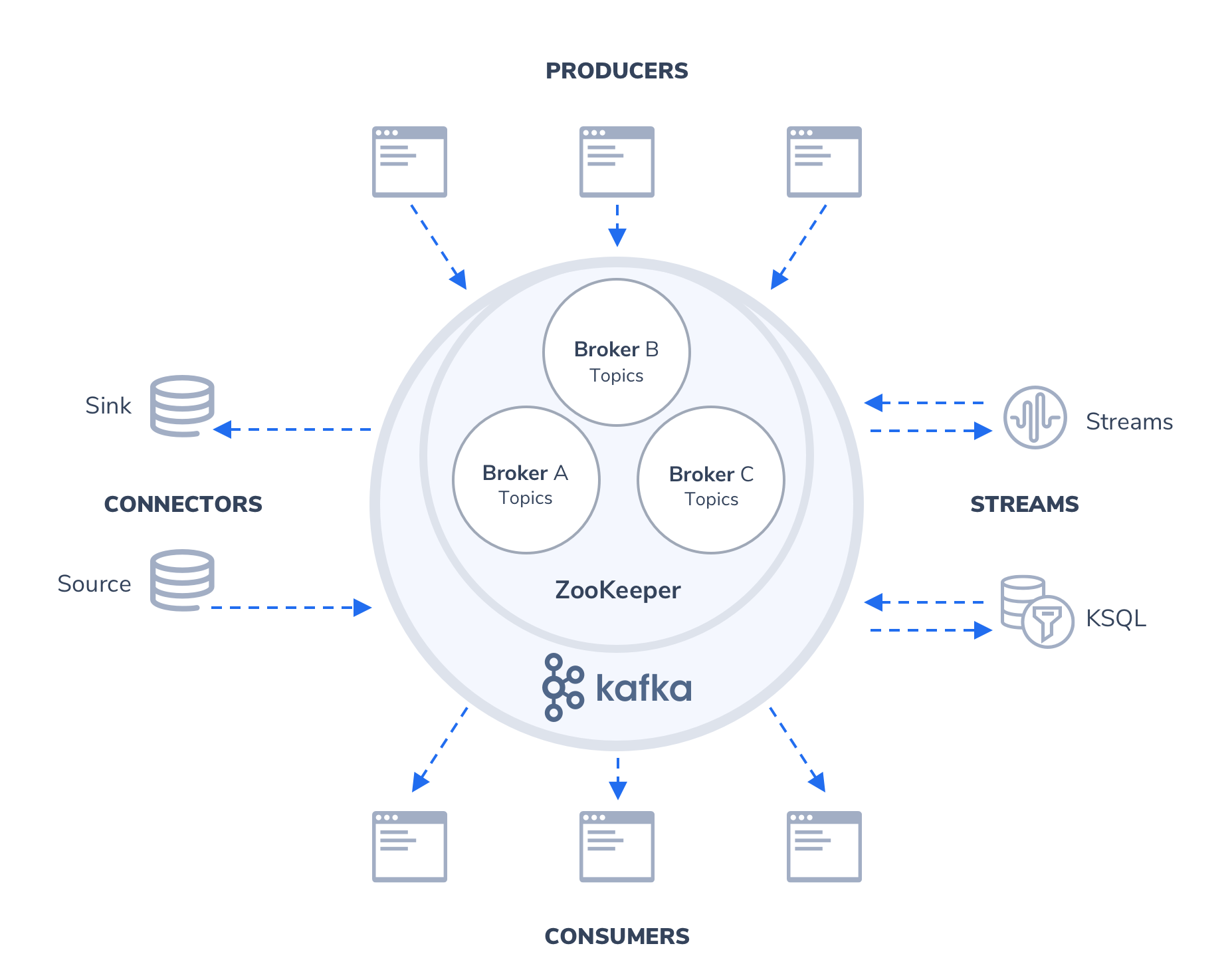
Спроектирован как распределённая, горизонтально масштабируемая система, обеспечивающая наращивание пропускной способности как при росте числа и нагрузки со стороны источников, так и количества систем-подписчиков. Подписчики могут быть объединены в группы. Поддерживается возможность временного хранения данных для последующей пакетной обработки. Одной из особенностей реализации инструмента является применение техники, сходной с журналами транзакций, используемыми в системах управления базами данных.
Изначально разработан компанией LinkedIn, исходные коды проекта открыты в начале 2011 года.
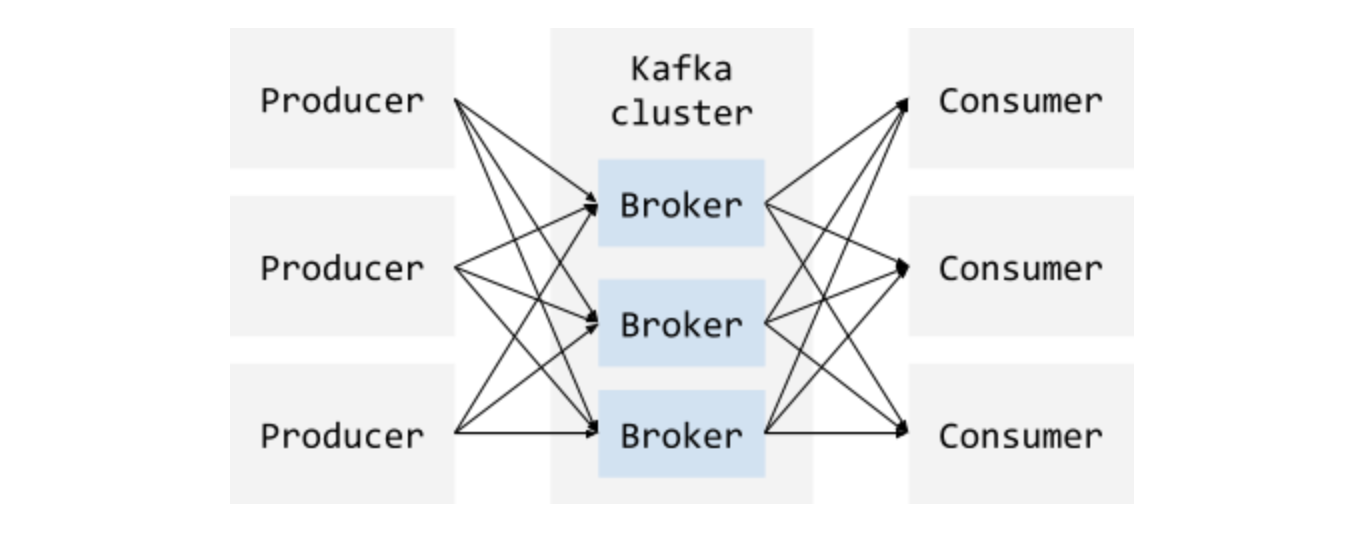
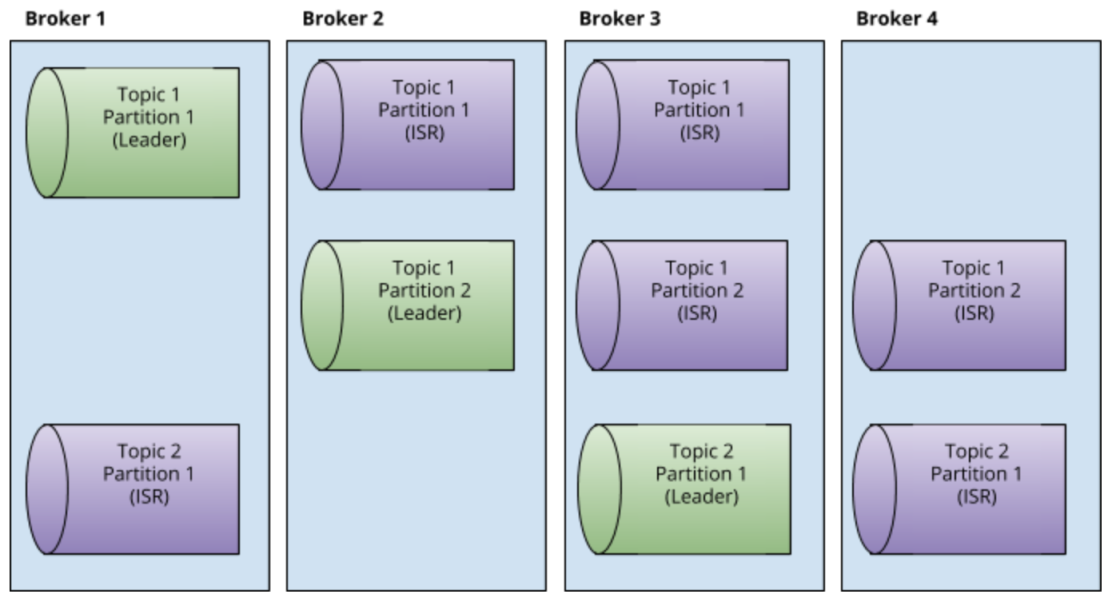
Кластер Apache Kafka состоит из узлов, один узел называется "брокер". Кластер хранит данные в топиках. Каждый топик состоит из одной или более партиций. Для отказоустойчивости каждая партиция продублирована на нескольких брокерах. Каждая партиция хранит сообщения, каждое сообщение в партиции имеет порядковый номер - оффсет.
Приложения могут записывать сообщения в топик посредством клиента producer, и читать посредством клиента consumer.
Сообщения
- Kafka не знает, что записано в сообщениях и не анализирует их.
- Каждое сообщение содержит timestamp момента записи
- Для снижения количества обращений и повышения пропускной способности сообщения объединяются в batch (но это снижает время отклика, поэтому размер батча нужно выбирать такой, чтобы удовлетворял обоим требованиям).
- Сообщение по умолчанию не может быть больше 1 Мб.
Брокеры
- Брокеры обрабатывают запросы: metadata (запросить у любого брокера партиции, реплики и лидеров по списку топиков, т.к. каждый брокер имеет metadata cache), produce (записать сообщения), fetch (прочитать сообщения). В конфигурации у клиента прописывается не менее двух любых брокеров, которые по запросу metadata сообщают адреса остальных брокеров.
- Один брокер избирается контроллером кластера (каждый брокер пытается стать контроллером, создавая ноду в zookeeper - если она существует, подписывается на ее удаление). Контроллер кластера избирает лидеров партиций и переизбирает их при выходе брокеров из строя (следя за брокерами путем подписания на их ноды в zookeeper). Для защиты от split brain (двух контроллеров), каждый контроллер использует epoch number, монотонно возрастающий при избрании нового контроллера.
- Контроллер следит за репликами партиций. Если реплика не прочитала последний offset за 10 секунд, она считается отстающей и не может стать лидером. Как только реплика стала отстающей, лидер перестает дожидаться ее для commit message (после чего сообщение может быть прочитано consumer).
- Брокер гарантирует, что порядок записи в партицию будет соответствовать порядку получения сообщений брокером. Однако, если producer отправляет следующее сообщение, не дождавшись подтверждения первого (max.inflight > 1), то одно из сообщений может не дойти или дойти позже последующего сообщения, что приведет к изменению порядка получения относительно порядка отправки. Соответственно, для обеспечения строгой гарантии порядка сообщений внутри партиции (между партициями порядок гарантировать невозможно) необходимо снизить параметр max.inflight до 1, что снижает производительность отправки сообщений.
- Брокер пишет сообщения на диск, но при работе на Linux ожидает ответа о записи в кэш записи, а не реальной записи на диск - отказоустойчивость обеспечивается с помощью репликации.
- Kafka использует zero-copy для чтения данных с диска (или из кэша) и передачи непосредственно в сеть для consumer (за счет хранения и передачи сообщений в едином сжатом формате) - сообщения отправляются сразу с диска без создания дополнительных копий. Поддерживается сжатие Snappy, GZip, LZ4. Producer может передавать сжатые или несжатые сообщения. Если producer передает сжатые данные, то он объединяет несколько сообщений в одно wrapper message.
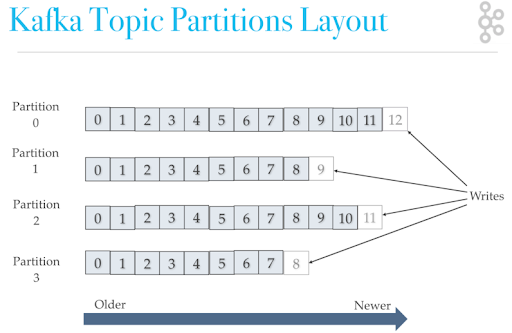
Партиции
- Кокретной партицией владеет один брокер-лидер (остальные брокеры, у которых также размещена эта партиция - реплики).
- Партиция должна целиком находиться на одном mount point одного брокера. При создании нового топика лидеры и реплики автоматически равномерно распределяются между брокерами и mount point следующим образом:
- Брокеры равномерно заполняются репликами (по количеству, а не по объему)
- На одном брокере не может находиться больше одной реплики конкретной партиции
- Если брокеры объединены в рэки, то по возможности реплики создаются в разных рэках.
- В рамках одного брокера реплики занимают сначала mount point где меньше всего партиций (нагрузка и свободное место в расчет не берутся).
- По умолчанию создается одна партиция на топик. Топики могут создаваться автоматически по обращению писателя или читателя. После создания топика количество партиций можно увеличить, но нельзя уменьшать.
- У партиции есть current leader broker и preferred leader broker (первый лидер партиции при ее создании, он же первый в списке реплик). По умолчанию preferred leader отбирает лидерство себе, выходя в онлайн - это позволяет приблизиться к исходной равномерной балансировке лидеров между брокерами.
- После записи в партицию очередного размера сегмента (1 Гб по умолчанию), сегмент (файл) закрывается и может просрочиться (по своему самому последнему времени или размеру партиции). Сегмент может быть закрыт по достижении времени (по умолчанию не выставлено) или размера. Закрытие сегмента по времени может приводить к лавине закрытий на одном брокере. Брокер держит открытый file handler для каждого сегмента, даже неактивного, поэтому нужно соответствующим образом настраивать ОС на работу с большим количеством открытых file handler.
- Топик может находиться в режиме compaction retention policy, в этом случае в неактивных сегментах хранятся только последние значения для уникальных ключей. Для удаления ключа нужно передать пару (ключ; null) - сначала брокер заменит значение на null, а после определенного времени (чтобы все consumers успели вычитать) удалит сообщение с этим ключом.
- Сообщения в партициях строго упорядочены, но не упорядочены между партициями одного топика, потому что запись сообщений в партиции происходит параллельно.
- Сообщения в партиции сохраняются до накопления определенного объема или периода хранения.
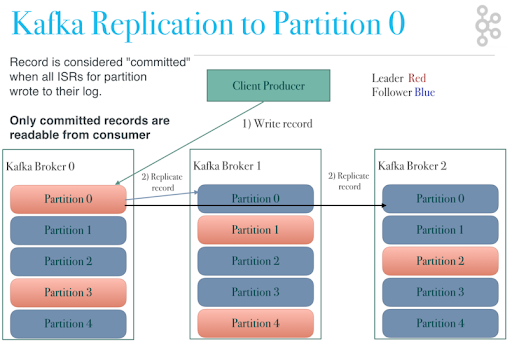
- Для каждого топика можно переопределить количество реплик (по умолчанию 3), минимальное количество in-sync реплик для разрешения записи producer. Если количество in-sync реплик меньше, то producer не смогут писать в партицию.
Producer
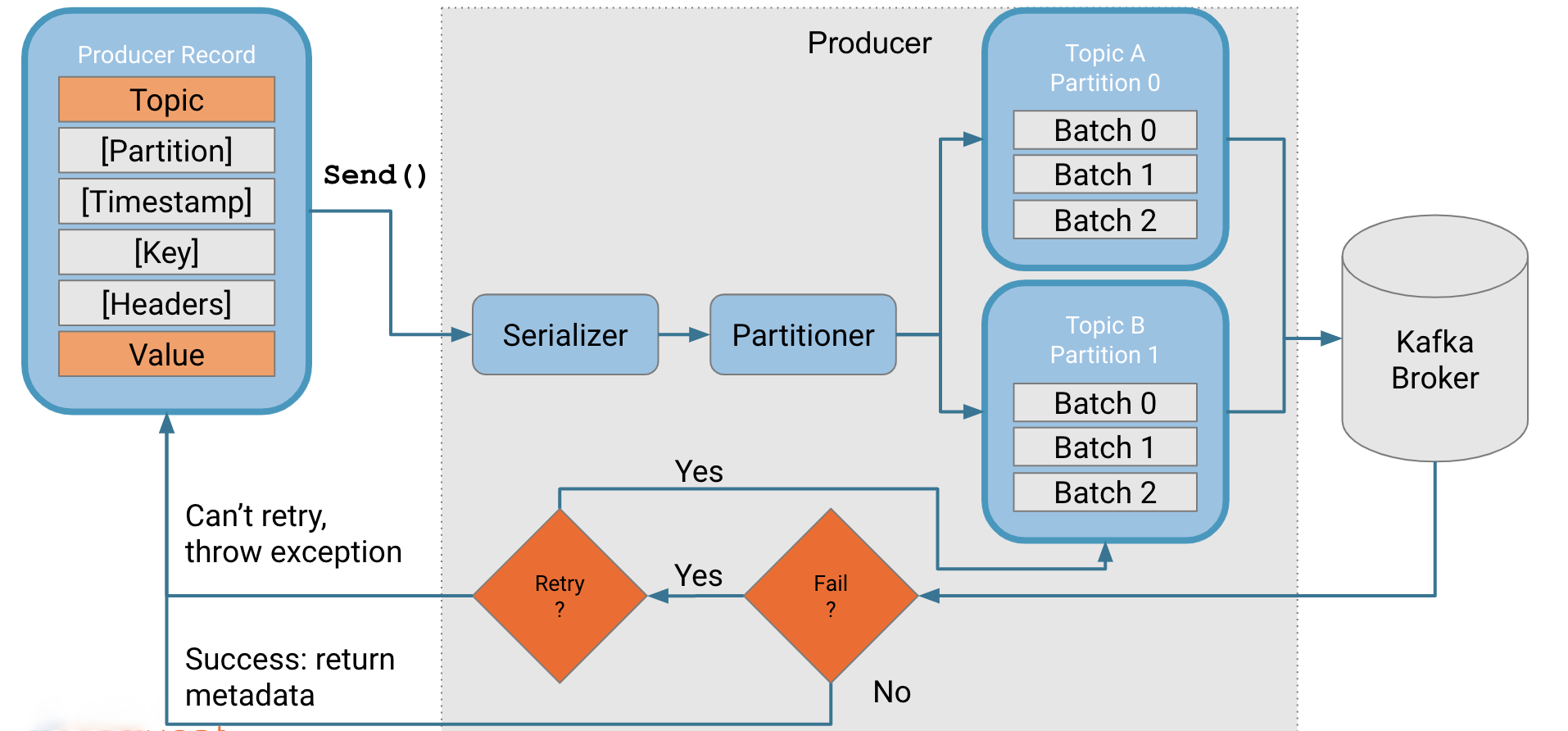
Producer - это клиент, который отправляет сообщения брокерам Kafka для их записи в партиции топиков.
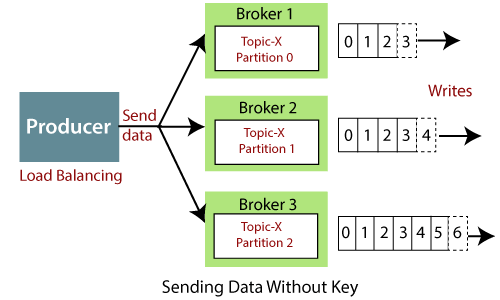
- Несколько producer могут писать в один топик. Каждый producer по умолчанию распределяет сообщения равномерно между всеми партициями: партиция будет выбрана из активных random round robin. Можно управлять распределением сообщений между партициями, но при этом выбор неактивной партиции вызовет ошибку:
- Можно явно указать партицию, в которую producer отправит данные.
- Можно указать ключ, по которому партиция будет определена методом хеширования.
- Можно задать свою функцию партиционирования, определяющую партицию для каждой строки.
- Producer кладет сообщения локально в отдельный батч для каждой комбинации топик-партиция. Ожидает превышения размера batch.size или времени linger.ms, чтобы нарастить батч дополнительными сообщениями. И затем отправляет батч брокеру.
Consumer
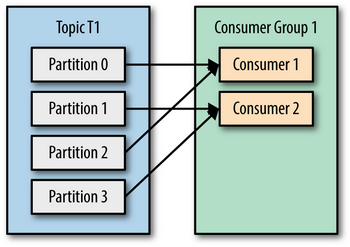
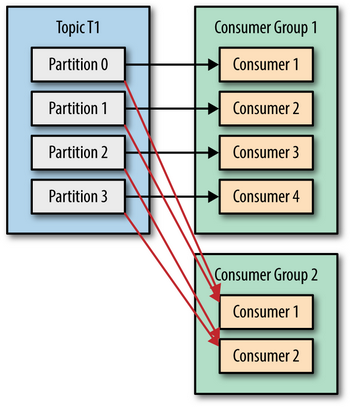
Consumer - это клиент, который читает сообщения из топика Kafka. Несколько consumer могут быть объединены в consumer group.
- Если consumer объединены в consumer group, то в каждой consumer group каждая партиция принадлежит только одному consumer (таким образом, consumer может читать несколько партиций, но одна партиция не может читаться несколькими consumer). Если количество consumer больше количества партиций, то часть consumer будет простаивать.
- Если consumers не объединены в consumer group, они читают независимо (то есть каждый consumer, не объединенный в consumer group, читает из всех партиций).
- Вход и выход любого consumer в группу сопровождается rebalance, в ходе которого все consumers привязываются к новым партициям, во время этой паузы ни один consumer не может читать, а после этой паузы все consumers вынуждены сбрасывать кеш чтения по потерянным в результате rebalance партициям (сообщения, уже вычитанные, но еще не обработанные придется выбросить, поскольку consumer не делал для них commit offset, а значит они будут повторно вычитаны другим consumer после rebalance). Первый подключившийся consumer в consumer group становится group leader и во время rebalance получает список consumers от group coordinator, определяя привязку consumers к partitions. Привязка возвращается к group coordinator, который распространяет ее на всех consumers в группе.
- Consumer может подписываться на топики по regular expression, в этом случае при создании соответствующего топика произойдет rebalance и consumer начнет читать также этот топик.
- Выход любого consumer из consumer group осуществляется либо по уведомлению от consumer к broker о выходе (clean exit) или за счет таймаута (несколько секунд) heartbeat отправляемых от consumer к брокеру, являющемуся group coordinator для данной consumer group.
- Consumer может сообщить брокеру, чтобы тот присылал батчи сообщений не больше (чтобы не переполнить память) и не меньше (чтобы не присылать слишком часто), а также указать время хранения первого сообщения батча, после которого брокер должен отправить батч в сторону consumer даже если он меньше указанного ограничения.
- Consumer может читать только после того, как сообщение запишется на все неотстающие реплики, для того чтобы гарантировать, что прочитанные сообщения не пропадут из kafka при сбое (из-за выхода из строя лидера, если сообщения есть только на нем) и смогут быть прочитаны всеми consumers. Чем больше реплике позволено отставать и при этом все еще считаться "неотстающей", тем больше может быть пауза между записью producer и чтением consumer (потому что consumer сможет читать только после записи сообщения на самую отстающую реплику, которая все еще считается "неотстающей").
- Для того, чтобы при выходе consumer из строя было известно, какие сообщения он успел прочитать, consumer делает commit offset - записывает оффсет последнего записанного сообщения. Раньше consumer записывал оффсеты в zookeeper. Теперь consumer может записывать свой текущий offset в kafka (в специальный топик offsets topic) следующими способами:
- Auto-commit выполняется в начале poll запроса, если прошло достаточно времени, и комитит последний offset предыдущего poll.
- Можно делать commit вручную синхронно (обычно перед выходом) или асинхронно (обычно в чтения сообщений), при этом можно дополнительно указать промежуточный offset или добавить callback для повторного комита в случае ошибки комита (в callback нужно следить, не устарел ли commit, чтобы не закомитить старый офсет поверх более свежего). Так можно комитить чаще, чем poll, а значит комитить не полный батч, а часть батча, которая уже обработана.
- Предыдущие варианты не позволяют атомарно обработать данные и записать commit, потому что в результате сбоя данные могут быть обработаны, но commit не произойдет. Атомарности можно добиться, записывая commit offset в свою базу вместе с обработанными данными в одной транзакции, а при инициализации consumer отправить брокеру, с какого оффсета ему нужно отправлять сообщения: seek(offset).
- Consumer может вручную подписаться на определенные партиции топика (например, все), не входя в consumer group, но в этом случае он должен периодически уточнять, не появились ли новые партиции, потому что в случае ручной подписки добавление партиций не приведет к rebalance.
- Если consumer не сильно отстает от producer, то он успевает вычитать данные, еще находящиеся в кеше (RAM) брокера. Поэтому начиная с определенной задержки между producer и consumer, когда записанные сообщения перестают помещаться в кэше, чтение может стать медленнее.
- Consumer может подписаться на подключение и отключение от него партиций:
- Отключение партиций вызывается перед rebalance - в этот момент consumer может остановить обработку и сделать синхронный коммит оффсетов в отключаемых партициях.
- Подключение партиций вызывается после rebalance - можно использовать для того, чтобы запросить оффсет в своей базе и перейти (seek) к нужному оффсету в партиции, если consumer хранит партиции в своей базе данных.
- В случае, если consumer не смог успешно обработать часть полученных сообщений из-за retriable error и хочет обработать их позже, он может:
- Закоммитить последний успешно обработанный оффсет. В этом случае при рестарте consumer он сможет обработать неуспешно обработанные сообщения еще раз, но может получить дубли других успешно обработанных сообщений.
- Записать неуспешно обработанные сообщения в отдельный топик. На этот топик может быть подписана отдельная consumer group или один из consumers может быть подписан на оба топика (dead-letter queue system).
Отказоустойчивость
Границы кластера
Kafka был спроектирован с учетом размещения всех клиентов и брокеров кластера в сети с низкими задержками и высокой пропускной способностью. Поэтому:
- Не рекомендуется размещать брокеры одного кластера в разных датацентрах.
- Не рекомендуется отправлять (produce) данные брокеру в удаленный датацентр (может быть больше сетевых ошибок)
- Можно при необходимости разделять consumer и брокеры в разные датацентры (в случае сетевых ошибок и задержек брокер будет накапливать данные). Однако, это может привести к неэффективному расходу пропускной способности, если несколько consumer groups будут забирать данные с одного удаленного кластера - эффективнее сначала реплицировать данные в локальный кластер).
Репликация между кластерами
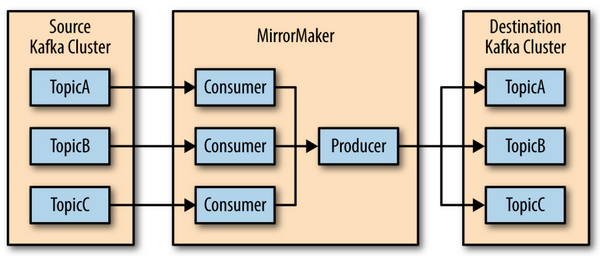
Репликацию между кластерами Kafka выполняет MirrorMaker. Один процесс MirrorMaker запускается для набора топиков одного кластера и представляет собой несколько consumers в одной consumer group и одного общего producer. MirrorMaker делает commit offset после того, как брокер подтвердил прием сообщений от producer MirrorMaker. MirrorMaker должен по возможности находиться в целевом датацентре, куда выполняется репликация - иначе при нарушении связи сообщения могут быть вычитаны и не записаны (в случае необходимости можно разместить MirrorMaker в исходном датаценте, но в этом случае обязательно указывать что все брокеры целевого кластера должны подтвердить получение батча - acks=all - и большое количество повторных попыток). MirrorMaker закрывается, если не может отправить сообщения.
Варианты архитектуры репликации:
- Hub and spokes (active-passive, spokes to hub) - используется в случаях, если в нецентральных датацентрах не требуется работать с данными других датацентров.
- Данные из кластеров разных датацентров реплицируются в кластер одного центрального датацентра, но оказываются там только eventually.
- Данные реплицируются один раз.
- Полный объем данных доступен только в центральном датацентре (при выходе его из строя не работает функциональность, требующая доступности всех данных).
- Active-active (самая надежная, гибкая, масштабируемая и эффективная, но конфликтная архитектура)
- Данные генерируются в двух датацентрах.
- Изменения внесенные в одном датацентре передаются в другой, но оказываются там только eventually.
- Оба датацентра владеют полным объемом данных.
- Двусторонняя синхронизация может приводить к конфликтам записи в разных датацентрах.
- Создаются логические топики для репликации (например для топика users: SF.users из одного ДЦ, NYC.users из другого ДЦ, .users со всеми сообщениями для consumers).
- Active-Standby (высокая надежность, универсальность, но трата ресурсов)
- Один из кластеров не работает, а только принимает реплики
Гарантии Kafka
- Порядок внутри партиции: если сообщение А записано producer в партицию после сообщения Б, то они будут прочитаны из этой партиции в том же порядке и сообщение А будет иметь меньший оффсет. Чтобы сообщения были записаны в партицию в порядке их отправки с producer, producer должен ждать подтверждения записи каждого батча прежде чем отправлять следующий (иначе из-за повторов после ошибок батч может быть записан после последующего за ним). Это обеспечивает строгий порядок, но снижает пропускную способность.
- Варианты отправки подтверждения записи сообщения от брокера в сторону producer:
- При ack=0 producer получает положительный ответ при успешной отправке по сети, но до записи сообщения (даже если партиция или кластер в оффлайне).
- При ack=1 producer получает положительный ответ после записи сообщения на диск (или в кэш) на лидере партиции. Данные могут потеряться, если лидер упадет сразу после получения сообщения, не успев реплицировать сообщения.
- При ack=all producer получает положительный ответ после записи сообщения на диск (или в кэш) на всех репликах партиции (когда сообщение получает статус committed message)
- Committed messages не будут потеряны до тех пор, пока хотя бы один брокер с неотстающей репликой продолжает работать (если все реплики, на которые было записано сообщение, вышли из строя, то есть риск, что до выключения брокеров данные еще не записались на диск и потеряются при выключении брокера).
- С включенной настройкой idempotence повторные получения batch с тем же sequence number от producer будут игнорироваться лидером (полученные номера пишутся в replication log и при выходе из строя лидера не потеряются).
- Consumers могут читать только committed messages, что гарантирует, что все consumers прочитают одни и те же сообщения, пока работает хотя бы одна неотстающая реплика.
- Поддерживается атомарная запись в несколько топиков в рамках одной транзакции. Consumer может читать в режимах:
- read_committed - в этом режиме consumer прочтет сообщения, записанные в рамках транзакции, только после коммита транзакции.
- read_uncommitted - в этом режиме consumer прочтет сообщения, записанные в рамках транзакции сразу после их записи, не дожидаясь коммита транзакции.
- Kafka дает гарантии чтения committed messages at-least-once, но не exactly-once. Exactly-once чтение можно достичь одним из следующих способов:
- Писать обработанные сообщения в другой топик kafka, при этом в той же транзакции делать commit offset. Для этого после выхода из consumer poll нужно начать транзакцию, записать в топик, сделать commit offset и сделать commit transaction.
- Записывать прочитанные из топика сообщения в базу данных, поддерживающую уникальные ключи и таким образом, игнорирующую повторную запись.
- Записывать прочитанные из топика сообщения в базу данных вместе с записью оффсета в эту же базу данных в одной транзакции. При инициализации сообщить consumer последний прочитанный оффсет с помощью команды seek.
Баланс между консистентностью и доступностью можно регулировать в том числе с помощью опции unclean election: включается на уровне кластера. Если последняя in-sync реплика выключилась, можно выбрать лидера из отстающих реплик, теряя сообщения, недополученные этой репликой, в том числе те, которые уже были прочитаны частью consumers, но за счет этого сохранить доступность партиции для записи (повышенная доступность за счет снижения консистентности). Либо запретить unclean election и ждать появления in-sync реплики (консистентность за счет пониженной доступности).
Переключение активного кластера
- Незапланированное переключение активного кластера на другой кластер невозможно без потери данных и/или дублирования сообщений из-за того, что репликация асинхронная. При запланированном переключении можно остановить основной кластер и дождаться окончания репликации перед переключением для избежания этих проблем.
- Варианты определения стартовых оффсетов consumers после переключения кластера:
- Можно сбрасывать consumers на начало (будет прочитано много дубликатов сообщений) или конец (часть сообщений может быть потеряна) топика.
- Можно использовать оффсеты из реплицированного топика __consumer_offsets, это снижает количество прочитанных дубликатов и потерянных сообщений, но не исключает их полностью:
- Оффсеты могут не совпадать между кластерами.
- Коммит оффсета может реплицироваться раньше самой записи по этому оффсету (часть данных будет потеряна).
- Коммит оффсета реплицируется с задержкой (будут прочитаны дубликаты сообщений).
- Можно использовать таймстемпы сообщений и при переключении кластера продолжать обрабатывать сообщения после таймстемпа аварии (kafka позволяет определить offset по таймстемпу). Этот метод позволит определить время, после которого данные были потеряны после переключения на резервный кластер. Позволяет снизить расхождения, связанные с расхождением оффсетов между кластерами.
- Можно использовать отдельное катастрофоустойчивое хранилище для синхронизации оффсетов при их репликации. При переключении кластеров используется для определения оффсета на резервном кластере по оффсету основного кластера. Это решение устраняет расхождения из-за несовпадения оффсетов, но имеет те же остальные проблемы: задержка репликации коммитов оффсетов или их репликация раньше самих записей.
- После переключения на другой кластер consumers должны начать с ним работать, для этого обычно используется переключение через DNS. Consumers должны переподключиться и новые оффсеты.
- После восстановления работы бывшего основного кластера можно начать реплицировать данные в его сторону с нового основного (который был резервным). При этом лучше стереть все записи на бывшем основном кластере и не реплицировать записи, записанные на новый основной до момента начала репликации, потому что в противном случае сложно определить, с какого момента начинать репликацию, а также бывший основной кластер может содержать записи, отсутствующие на новом основном.
Кросс-датацентровые (stretch) кластеры
Брокеры stretch кластера располагаются в двух датацентрах. Producers получают подтверждения после записи на брокеры в оба датацентра (acks=all), что по сути означает синхронную репликацию. Таким образом в отличие от режима Active-standby, используются ресурсы обоих датацентров. Проблемы решения:
- Не защищает от сбоев приложения или kafka.
- Требует большой пропускной способности и низких задержек между датацентрами.
- Для автоматического переключения с использованием ZooKeeper требуется не менее трех датацентров. Для ручного переклчения достаточно двух (редко используется).
Kafka connect
Kafka Connect - набор готовых коннекторов к известным продуктам хранилищам данных (может использоваться не разработчиком). Идет в комплекте и устанавливается вместе с Apache Kafka.
- Kafka Connect API - более высокоуровневый API по сравнению с API consumer и producer, дополнительно поддерживает управление конфигурацией, хранение оффсетов, параллелизацию, обработку ошибок, REST интерфейс управления. Используется для интеграции с хранилищами данных, для которых нет готовых коннекторов.
- Kafka Connect - это кластер worker processes.
- Если объем данных, проходящих через Connect большой, лучше выделить для него серверы, отдельные от брокеров.
Потоковая обработка данных
Архитектура преобразования данных
- ETL (Extract-Transform-Load) - перемещает логику трансформации в pipeline и ограничивает возможности принимающей стороны.
- ELT (Extract-Load-Transform) - архитектура data lake или high-fidelity pipeline. Обработка выполняется на принимающей стороне.
Паттерны потоковой обработки
- Обработка отдельных событий (map). Отсутствие состояния позволяет обрабатывать каждую строку независимо и переключение партиций между обработчиками в любой момент.
- Обработка с хранением локального состояния (reduce). Обработчик каждой партиции должен хранить данные в памяти для простоты, на диске для надежности и отправлять в общее хранилище для возможности переключения.
- Многофазная обработка с перепартиционированием (reduce-reduce). Например, на первой фазе при обработке отдельных партиций обработчики получают локальные результаты, которые затем публикуют в общий топик, разбираемый единым процессом, агрегирующим результаты с разных исходных партиций.
- Обработка с подключением внешних данных (join).
- Простой способ - делать запрос в базу за дополнительной информацией для каждой обрабатываемой строки.
- Более производительный способ - хранить кэш данных из БД, получая изменения от базы посредством отправки изменений в БД в топик - CDC (Change data capture).
- Объединение нескольких потоков (streaming join). Вместо обработки всего бесконечного потока объединение происходит в рамках временных окон. Для сокращения объема хранимой в состоянии информации, происходит партиционирование обоих потоков по одному принципу, что позволяет обработчику подписаться на одинаковые партиции обоих топиков и получать всю необходимую информацию по ограниченному набору ключей. Далее обработчик хранит в памяти информацию по обрабатываемому окну для выполнения объединения.
- При необходимости обновления агрегированной информации за прошлые периоды необходимо хранить все исходные данные для прошлых временных окон. Для ограничения используемых ресурсов ограничивается максимальный возраст дополняемых окон.